The arrival of AI has changed the way we browse the internet. We no longer rely solely on search engines like Google; instead, we interact with intelligent tools that process the web for us. This shift solidifies the emergence of AI optimization (AIO). It raises a key question: Should websites display themselves to us the same way they do to an AI simply searching for data?
While we see an attractive website with animations, a Large Language Model (LLM) sees a jungle of HTML code and scripts. The llms.txt standard has emerged to eliminate that visual clutter and provide direct access to your information.
What is llms.txt?
The llms.txt file, located at the root of a domain (/llms.txt), is a proposed standard designed to help large language models (LLMs), such as ChatGPT, Gemini, or Claude, efficiently understand and process website content.
While other standards like robots.txt manage crawler access and sitemaps facilitate URL indexing, llms.txt was created with the purpose of acting as a cover letter for Artificial Intelligence to offer machines a clean and structured narrative, eliminating code layers (HTML, CSS, or JS) that often hinder pure data extraction.
"Ignore the code clutter. Here is exactly who we are, what we do, and where our most valuable information is, clean and ready to use."
At this point, the question is inevitable: Why implement it?
What benefits does adopting llms.txt offer?
The implementation of this file responds to two critical needs: efficiency in data processing and control over your brand identity with AIs.
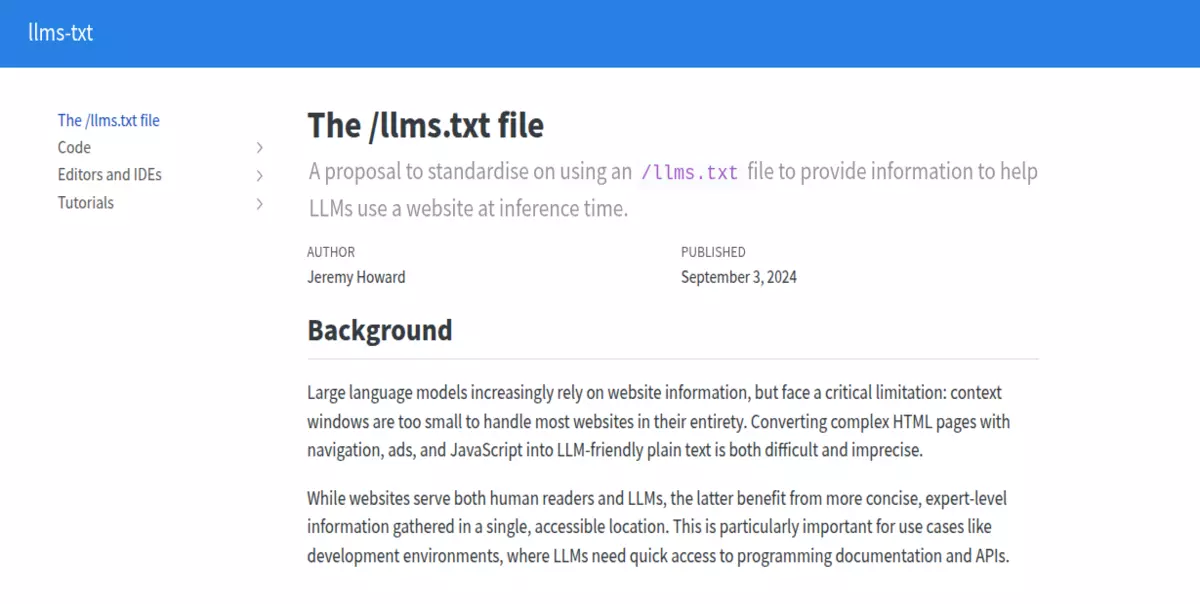
Official website llms.txt (https://llmstxt.org/)
Facilitating AI comprehension and efficiency:
AIs operate under time and processing capacity constraints. Facilitating information for them solves two fundamental technical problems:
- Reduction of "Noise": A website is usually composed of a high percentage of code (HTML, CSS, JS) and only a fraction of useful, valuable content. By removing the technical wrapper, you prevent the AI from misinterpreting the data or breaking the logical structure of the content during its cleaning process.
- Optimization of the Context Window: LLMs have a limited memory known as the context window. If the model receives a code-saturated website, it wastes its capacity on irrelevant information. With the llms.txt standard, you provide valuable information.
Taking charge of your digital narrative:
Without a clear standard, AIs must "interpret" what you do based on scattered captured fragments. This often leads to incomplete or inaccurate information.
With the file, you organize the narrative: you explicitly define who you are, what you do, and what your differentiating values are. You move from passive interpretation by the machine to direct communication where you dictate what the AI should know about your brand.
Visibility (AIO):
Beyond technical efficiency, there is a strategic marketing benefit: visibility. The correct implementation of this standard makes it easier for AI models to identify your site as a structured and reliable information source. This not only improves the accuracy with which Artificial Intelligence speaks about your brand, but also increases the chances of being cited in generated responses, driving traffic to your website.
Now that we have seen its benefits, let's look at how the llms.txt file is built and how to implement it on our Drupal website.
Is it really necessary? Standard adoption and use cases
Being pragmatic, as of today there is no official confirmation from giants like OpenAI, Google, or Anthropic stating that their crawlers use this file directly in their algorithms. However, in the realm of AI Optimization (AIO), llms.txt has consolidated itself as a fundamental first step for any site aspiring to be "AI-Ready".
Although the standard is young, leading IT and developer-oriented companies have already begun to adopt it as a practice:
| Company | Implementation Strategy | Reference |
|---|---|---|
| Anthropic | Uses the standard to facilitate the direct ingestion of its technical documentation by models like Claude. | View llms.txt |
| OpenAI | Employs a summary file that links to an llms-full.txt to offer technical depth without saturating the AI's initial memory. | View llms.txt |
| Nvidia | Acts as a centralizing index, chaining several specialized files to create a hierarchically structured context network. | View llms.txt |
| Amazon (AWS) | Facilitates AIs in assisting with precision in the configuration of complex architectures through optimized documentation. | View llms.txt |
Additionally, globally specialized SEO companies, such as Semrush or WordLift, already actively recommend it and even integrate it as a factor to consider when using their semantic optimization and auditing tools.
Adopting llms.txt now does not guarantee magical results, but it prepares your website's infrastructure for a future where readability for machines will be as critical as loading speed is for humans today.
Crafting the llms.txt file
Building a truly useful llms.txt file requires combining technical structure with a strategic approach. It's not just about creating a document, but organizing it to function as a clear and effective tool. To do this, we will divide this process into three stages.
1. File structure
Following the specifications of llmstxt.org, the standard uses Markdown to inject context efficiently. Being the "native language" that AIs analyze most easily, it guarantees an optimized technical structure that remains perfectly readable for humans.
For optimal processing, we must organize the information following this structural logic:
| Element | Markdown Syntax | Function for AI | Example |
|---|---|---|---|
| Title (h1) | # Name | Unique and mandatory identifier for the website. | # Metadrop |
| Site Summary | > Description | Acts as a "system instruction" to provide global context. | > Drupal experts. |
| Sections (h2, h3...) | ## Section### Subsection | Groups and categorizes information thematically. | ## Services### Web development |
| Lists | - Item 1- Item 2 | Organizes information within a section. | - Technical audit- User experience (UX) design |
| Links | - [T](URL): Note | The note explains the content so the AI can decide whether to crawl it. | - [SEO](url): SEO guide. |
The ## Optional section tells the AI what content it can skip if it needs a shorter or quicker context. It is the ideal place to include secondary information, allowing the model to prioritize your business's most critical data.
Additionally, if your website is very large, the standard recommends using two complementary files to manage information depth:
- llms.txt: An executive summary of the site's key resources. It is the first stop for the AI and should be brief and direct.
- llms-full.txt (Optional): A file that includes more extensive information linked from the main file, to offer more details without saturating the initial context window.
Implementation example:
# Website Name
> Brief description of your website.
## Our Services
- [Service I](https://example.com/service-I): Brief summary of the functionality and main benefit it offers.
- [Service II](https://example.com/service-II): Brief summary of the functionality and main benefit it offers.
- [Service III](https://example.com/service-III): Brief summary of the functionality and main benefit it offers.
## Main Solutions
- [Solution A](https://example.com/solution-A): Brief description of the solution provided.
- [Solution B](https://example.com/solution-B): Brief description of the solution provided.
- [Solution C](https://example.com/solution-C): Brief description of the solution provided.
## Resources and Information
- [Content Title One](https://example.com/resource-one): Brief explanation of the topic covered in this link and why it is useful.
- [Content Title Two](https://example.com/resource-two): Brief explanation of the topic covered in this link and why it is useful.
## Optional
- [Social Media](https://example.com/social): Links to external profiles to follow the brand’s latest news.
- [Careers](https://example.com/career): Information for candidates and available job openings.Mastering technical syntax is just the first step. For the file to fulfill its function, it is not enough to know how to write it; we must decide what messages we will convey. Not everything that resides on your website deserves a space in your llms.txt.
2. Criteria: What to include and what to omit
Building an llms.txt file is not about dumping your entire database into a text document. Unlike an XML Sitemap, whose mission is to be an exhaustive inventory for Google to index every corner of your website, llms.txt is an exercise in strategic synthesis.
The goal is to provide the most efficient context possible for language models. An overloaded file not only wastes the "context window", but also introduces noise that can lead to inaccurate responses. To avoid this, we must filter the information.
Prioritizing information
Artificial Intelligence seeks to understand the essence of your business, not your old news. Select sections that provide real and useful information regardless of the date:
- Key services and solutions: Clearly define what you do, what you provide, and for whom.
- Success stories and methodology: Show how you solve problems and what your experience is.
- Technical documentation: High-value information that serves as a direct reference.
The exclusion filter: What gets left out?
To maintain the cleanliness of the file, it is essential to remove elements that only generate "noise":
- Temporary or outdated content: Last month's offers, ended events, or ephemeral news that confuse the model and become obsolete in days.
- Visual or interactive pages: If a page's value depends on animations, interactive elements, or complex graphics, its usefulness in a plain text environment is almost nil.
- Sensitive or proprietary material: Avoid exposing data that, when cited out of context by an AI, could lead to misinterpretation or compromise privacy.
The value of semantic description
In the llms.txt standard, a link without context is a missed opportunity. Do not just list URLs; add a description that explains what is behind that link. This allows the AI to decide whether it needs to crawl that page or if it already has enough information from your summary.
- Bad:
- [Services](/services) - Good:
- [Services](/services): Catalog of Drupal development solutions specializing in decoupled architectures and performance optimization.
Once these selection criteria are defined, the challenge is to keep the file updated without it becoming a manual workload. This is where automation and Drupal's ability to manage information dynamically come into play.
3. Implementation in Drupal
There are several alternatives to generate this file in Drupal; at Metadrop, we have chosen the /llms.txt module due to its flexibility and its integration with Drupal's native token system, which allows keeping the file updated without imposing a manual workload.
Module configuration
To configure the /llms.txt module, you just need to go to "Content > /llms.txt configuration (/admin/content/llms-txt)" and add the necessary information:
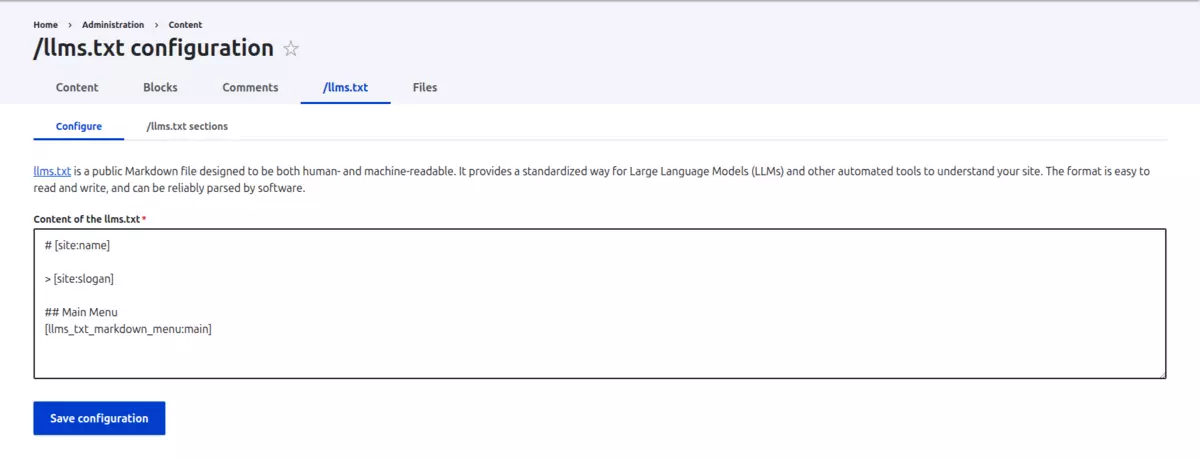
As we mentioned previously and as shown in the image, the information can be added using Drupal's native Token system.
Using Tokens and Menus:
The true power of the module lies in its integration with the Token system. You can configure the file by adding any token that Drupal offers. Additionally, the module includes automatically generated tokens based on menus, as shown below:
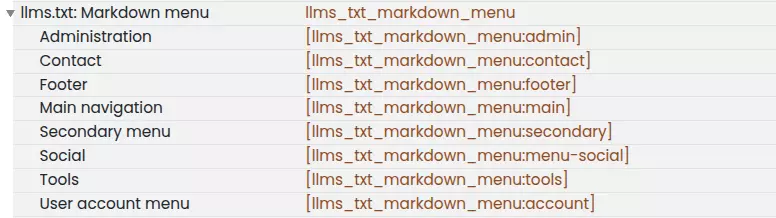
Based on the selected menu, the token extracts the link title, the URL, and most importantly, the menu item description to meet the semantic requirement we mentioned earlier.
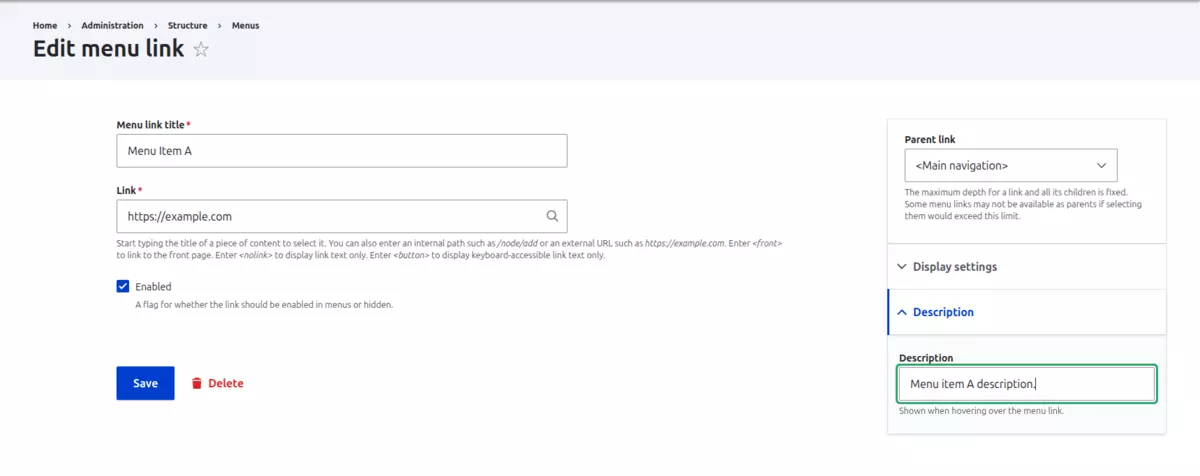
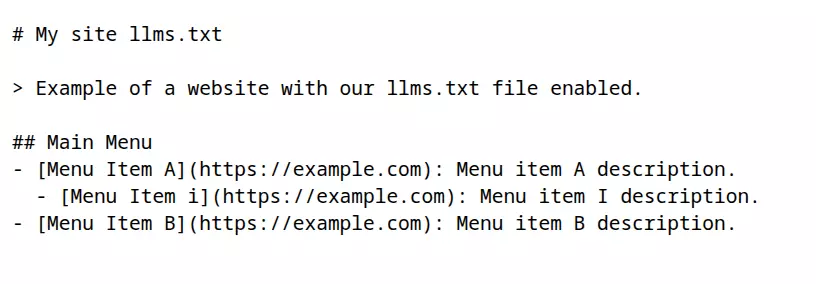
The result, using as an example the token that includes the main menu links, when navigating to the /llms.txt path would be the following:
Conclusion: Preparing for the future of search
In short, while it hasn’t yet been proven that the llms.txt standard improves search rankings in the same way as traditional SEO, its implementation is quick, seamless, and free of charge, making it a low-effort experiment with great potential for any forward-thinking brand.
Ultimately, AI is fundamentally transforming the traditional ways we have interacted with the internet until now. Embracing this change, even in an experimental capacity, is a strategic move to stay ahead of the curve, allowing us to observe firsthand how AI models are adopting and utilizing these new concepts to interpret our digital presence.
