Con la llegada de las IAs, ha cambiado el panorama de cómo navegamos por internet, ya no dependemos solo de buscadores como Google, sino que interactuamos con herramientas inteligentes que procesan la web por nosotros. Este cambio consolida el nacimiento del AIO (AI Optimization) y plantea una duda clave: ¿Debería presentarse una web a nosotros, igual que a una IA que solo busca datos?
Mientras nosotros vemos un diseño atractivo con animaciones, para un LLM (Large Language Model) tu web es un laberinto de código HTML y scripts. Para eliminar ese ruido visual y ofrecer una vía de acceso directa a tu información, aparece el estándar llms.txt.
¿Qué es llms.txt?
Ubicado en la raíz de un dominio (/llms.txt), el archivo llms.txt es un estándar propuesto para facilitar que los modelos de lenguaje (LLMs), como ChatGPT, Gemini o Claude, comprendan y procesen el contenido de un sitio web de forma eficiente.
Mientras que otros estándares como robots.txt gestionan el acceso de los rastreadores y los sitemaps facilitan la indexación de URLs, el llms.txt nace con el propósito de actuar como una carta de presentación para la Inteligencia Artificial para ofrecer a las máquinas una narrativa limpia y estructurada, eliminando capas de código (HTML, CSS o JS) que suelen dificultar la extracción de datos pura.
"Ignora el desorden del código. Aquí tienes exactamente quiénes somos, qué realizamos y dónde está nuestra información más valiosa, limpia y lista para usar".
Llegados a este punto, la pregunta es inevitable: ¿Por qué implementarlo?
¿Qué beneficios ofrece la adopción de llms.txt?
La implementación de este archivo responde a dos necesidades críticas: la eficiencia en el procesamiento de datos y el control de tu identidad de marca con las IAs.
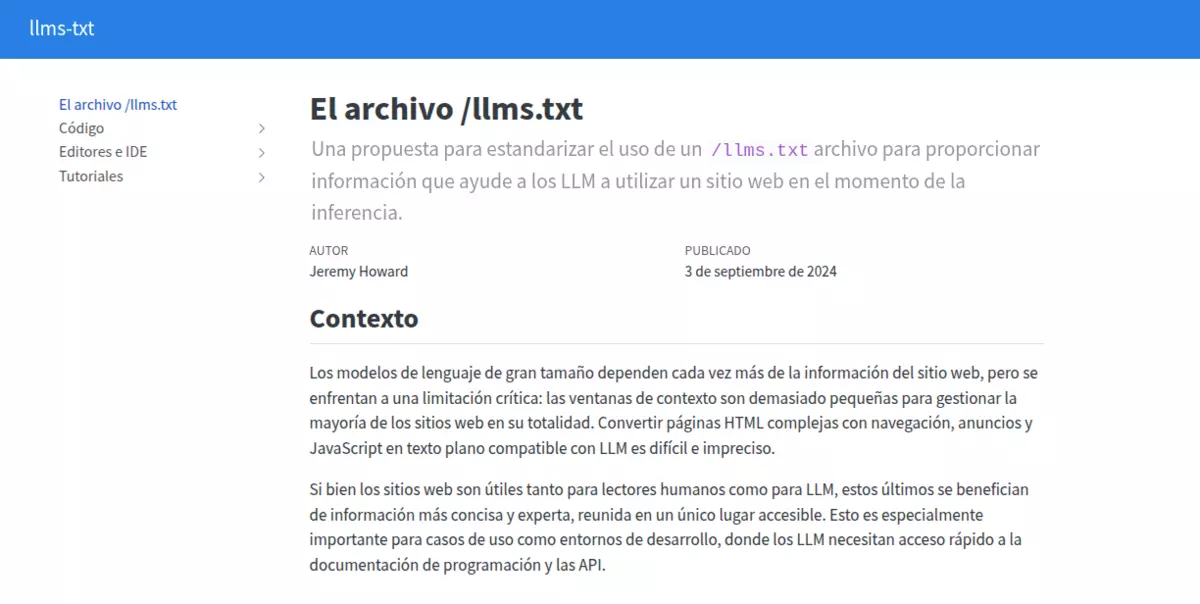
Web oficial llms.txt (https://llmstxt.org/)
Facilitar la comprensión y eficiencia de la IA:
Las IAs operan bajo restricciones de tiempo y capacidad de procesamiento. Facilitarles la información resuelve dos problemas técnicos fundamentales:
- Reducción de "Ruido": Una web suele estar compuesta por un elevado porcentaje de código (HTML, CSS, JS) y solo una parte de contenido de valor útil. Al eliminar el envoltorio técnico, evitas que la IA malinterprete los datos o rompa la estructura lógica del contenido durante su proceso de limpieza.
- Optimización de la Ventana de Contexto: Los LLMs tienen una memoria limitada denominada ventana de contexto. Si el modelo recibe una web saturada de código, desperdicia su capacidad con información irrelevante. Con el estándar llms.txt, ofreces información de valor.
Tomar el mando de tu narrativa digital:
Sin un estándar claro, las IAs deben "interpretar" a qué te dedicas basándose en fragmentos sueltos capturados. Esto suele derivar en información incompleta o inexacta.
Con el fichero, tú organizas la narrativa: defines explícitamente quién eres, qué haces y cuáles son tus valores diferenciales. Pasas de una interpretación pasiva por parte de la máquina a una comunicación directa donde tú dictas qué debe saber la IA sobre tu marca.
Visibilidad (AIO):
Más allá de la eficiencia técnica, existe un beneficio estratégico de marketing: la visibilidad. La correcta implementación de este estándar facilita que los modelos de IA identifiquen tu sitio como una fuente de información estructurada y fiable. Esto no solo mejora la precisión con la que la Inteligencia Artificial habla de tu marca, sino que aumenta las posibilidades de aparecer citado en las respuestas generadas, derivando tráfico hacia tu web.
Ahora que hemos visto sus beneficios, vamos a ver cómo se construye el fichero llms.txt e implementarlo en nuestro sitio web Drupal.
¿Es realmente necesario? Adopción del estándar y casos de uso
Siendo pragmáticos, a día de hoy no existe una confirmación oficial por parte de gigantes como OpenAI, Google o Anthropic que asegure que sus rastreadores utilizan este archivo de forma directa en sus algoritmos. Sin embargo, en el ámbito de la optimización para la IA (AIO), el llms.txt se ha consolidado como un primer paso fundamental para cualquier sitio que aspire a ser "AI-Ready".
Aunque el estándar es joven, empresas líderes en el sector IT y orientadas a desarrolladores ya han comenzado a adoptarlo como una práctica:
| Empresa | Estrategia de implementación | Referencia |
|---|---|---|
| Anthropic | Utiliza el estándar para facilitar la ingesta directa de su documentación técnica por parte de modelos como Claude. | Ver llms.txt |
| OpenAI | Emplea un archivo resumen que enlaza a un llms-full.txt para ofrecer profundidad técnica sin saturar la memoria inicial de la IA. | Ver llms.txt |
| Nvidia | Actúa como un índice centralizador, encadenando varios ficheros especializados para crear una red de contexto jerarquizada. | Ver llms.txt |
| Amazon (AWS) | Facilita que las IAs asistan con precisión en la configuración de arquitecturas complejas mediante documentación optimizada. | Ver llms.txt |
Adicionalmente, empresas especializadas en SEO a nivel mundial, como Semrush o WordLift, ya lo recomiendan activamente e incluso lo integran como factor a tener en cuenta al utilizar sus herramientas de auditoría y optimización semántica.
Adoptar el llms.txt ahora no garantiza resultados mágicos, pero prepara la infraestructura de tu sitio web para un futuro en el que la legibilidad para las máquinas será tan crítica como hoy lo es la velocidad de carga para los humanos.
Elaborando el archivo llms.txt
Construir un archivo llms.txt realmente útil exige combinar estructura técnica con un enfoque estratégico. No se trata simplemente de crear un documento, sino de organizarlo para que funcione como una herramienta clara y eficaz. Para ello, dividiremos este proceso en tres etapas.
1. Estructura del fichero
Atendiendo a las especificaciones de llmstxt.org, el estándar utiliza Markdown para inyectar contexto de forma eficiente. Al ser el "lenguaje nativo" que las IAs analizan con mayor facilidad, garantiza una estructura técnica optimizada que sigue siendo perfectamente legible para los humanos.
Para que el procesamiento sea óptimo, debemos organizar la información siguiendo esta lógica estructural:
| Elemento | Sintaxis Markdown | Función para la IA | Ejemplo |
|---|---|---|---|
| Título (h1) | # Nombre | Identificador único y obligatorio del sitio web. | # Metadrop |
| Resumen del Sitio | > Descripción | Actúa como "instrucción de sistema" para dar contexto global. | > Expertos en Drupal. |
| Secciones (h2, h3...) | ## Sección ### Subsección | Agrupa y categoriza la información temáticamente. | ## Servicios ### Desarrollo web |
| Listas | - Item 1 - Item 2 | Organiza la información dentro de una sección. | - Auditoría técnica - Diseño de experiencia de usuario (UX) |
| Enlaces | - [T](URL): Nota | La nota explica el contenido para que la IA decida si rastrearlo. | - [SEO](url): Guía de SEO. |
La sección ## Optional indica a la IA qué contenido puede omitir si necesita un contexto más breve o rápido. Es el lugar ideal para incluir información secundaria permitiendo que el modelo priorice los datos más críticos de tu negocio.
Adicionalmente, si tu sitio web es muy amplio, el estándar recomienda el uso de dos ficheros complementarios para gestionar la profundidad de la información:
- llms.txt: Un resumen ejecutivo de los recursos clave del sitio. Es la primera parada de la IA y debe ser breve y directa.
- llms-full.txt (Opcional): Un archivo que incluye información más extensa enlazado desde el archivo principal, para ofrecer más información sin saturar la ventana de contexto inicial.
Ejemplo de implementación:
# Nombre del sitio web
> Breve descripción de su sitio web.
## Nuestros servicios
- [Servicio I](https://example.com/servicio-I): Resumen breve de la funcionalidad y el beneficio principal que ofrece.
- [Servicio II](https://example.com/servicio-II): Resumen breve de la funcionalidad y el beneficio principal que ofrece.
- [Servicio III](https://example.com/servicio-III): Resumen breve de la funcionalidad y el beneficio principal que ofrece.
## Soluciones Principales
- [Solución A](https://example.com/solucion-A): Breve descripción de la solución aportada.
- [Solución B](https://example.com/solucion-B): Breve descripción de la solución aportada.
- [Solución C](https://example.com/solucion-C): Breve descripción de la solución aportada.
## Recursos e Información
- [Título del Contenido Uno](https://example.com/recurso-uno): Explicación breve sobre el tema tratado en este enlace y por qué es útil.
- [Título del Contenido Dos](https://example.com/recurso-dos): Explicación breve sobre el tema tratado en este enlace y por qué es útil.
## Optional
- [Redes Sociales](https://example.com/social): Enlaces a perfiles externos para seguir la actualidad de la marca.
- [Empleo](https://example.com/empleo): Información para candidatos y vacantes disponibles.Dominar la sintaxis técnica es solo el primer paso. Para que el archivo cumpla su función, no basta con saber escribirlo, debemos decidir qué mensajes vamos a transmitir. No todo lo que reside en tu web merece un espacio en tu llms.txt.
2. Criterios: Qué incluir y qué omitir
Construir un archivo llms.txt no consiste en volcar toda tu base de datos en un documento de texto. A diferencia de un Sitemap XML, cuya misión es ser un inventario exhaustivo para que Google indexe cada rincón de tu web, el llms.txt es un ejercicio de síntesis estratégica.
El objetivo es proporcionar el contexto más eficiente posible para los modelos de lenguaje. Un archivo sobrecargado no solo desperdicia la "ventana de contexto", sino que introduce ruido que puede derivar en respuestas imprecisas. Para evitarlo, debemos filtrar la información.
Priorizar la información
La Inteligencia Artificial busca entender la esencia de tu negocio, no tus noticias de hace tiempo. Selecciona las secciones que proporcionen información real y útil independientemente de la fecha:
- Servicios y soluciones clave: Define qué haces, qué aportas y para quién de forma clara.
- Casos de éxito y metodología: Muestra cómo resuelves problemas y cuál es tu experiencia.
- Documentación técnica: Información de alto valor que sirva de referencia directa.
El filtro de exclusión: ¿Qué queda fuera?
Para mantener la limpieza del archivo, es fundamental eliminar elementos que solo generan "ruido":
- Contenido temporal o caduco: Ofertas del mes pasado, eventos finalizados o noticias efímeras que confunden al modelo y quedan obsoletas en días.
- Páginas visuales o interactivas: Si el valor de una página depende de animaciones, elementos interactivos o gráficos complejos, su utilidad en un entorno de texto plano es casi nula.
- Material sensible o propietario: Evita exponer datos que, al ser citados fuera de contexto por una IA, puedan dar lugar a malinterpretaciones o comprometer la privacidad.
El valor de la descripción semántica
En el estándar llms.txt, un enlace sin contexto es una oportunidad perdida. No te limites a listar URLs, añade una descripción que explique qué hay detrás de ese enlace. Esto permite que la IA decida si necesita rastrear esa página o si ya tiene suficiente información con tu resumen.
- Mal:
- [Servicios](/servicios) - Bien:
- [Servicios](/servicios): Catálogo de soluciones de desarrollo Drupal especializado en arquitecturas desacopladas y optimización de rendimiento.
Una vez definidos estos criterios de selección, el reto es mantener el archivo actualizado sin que suponga una carga de trabajo manual. Aquí es donde entra en juego la automatización y la capacidad de Drupal para gestionar la información de forma dinámica.
3. Implementación en Drupal
Existen varias alternativas para generar este archivo en Drupal, en Metadrop hemos optado por el módulo /llms.txt por su flexibilidad y por su integración con el sistema nativo de tokens de Drupal, que permite mantener el archivo actualizado sin que suponga una carga de trabajo manual.
Configuración del módulo
Para configurar el módulo /llms.txt, solo tienes que ir a "Content > /llms.txt configuration (/admin/content/llms-txt)" y añadir la información necesaria:
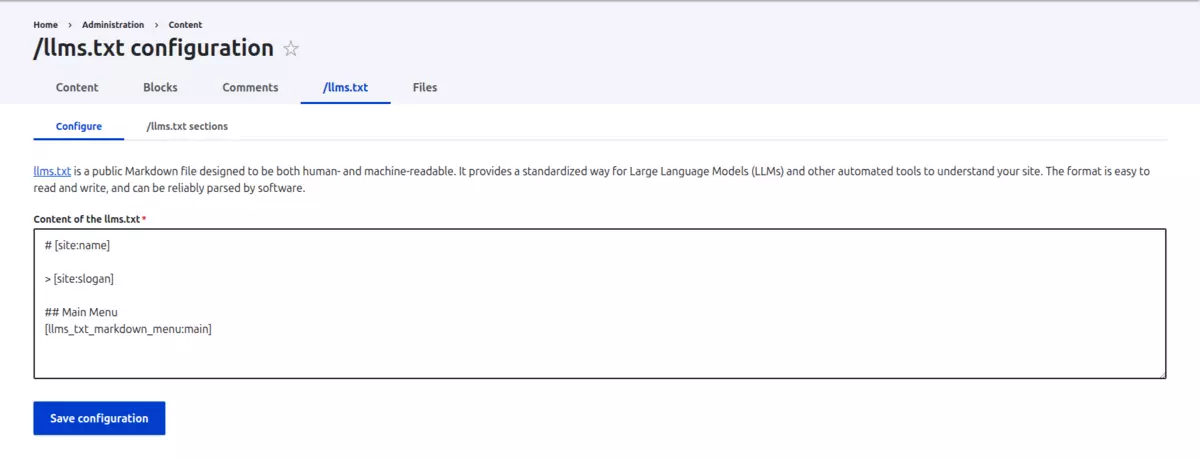
Como avanzábamos previamente y se muestra en la imagen, la información puede ser añadida utilizando el sistema de Tokens nativo de Drupal.
Uso de Tokens y Menús:
La verdadera potencia del módulo reside en su integración con el sistema de Tokens. Puedes configurar el archivo añadiendo cualquier token que ofrezca Drupal. Además, el módulo incluye tokens generados automáticamente a partir de los menús, como se muestra a continuación:
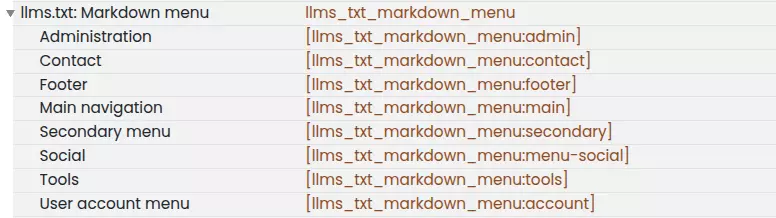
El token, a partir del menú seleccionado, extrae el título del enlace, la URL y, lo más importante, la descripción del elemento de menú para cumplir con el requisito de semántica que mencionamos anteriormente.
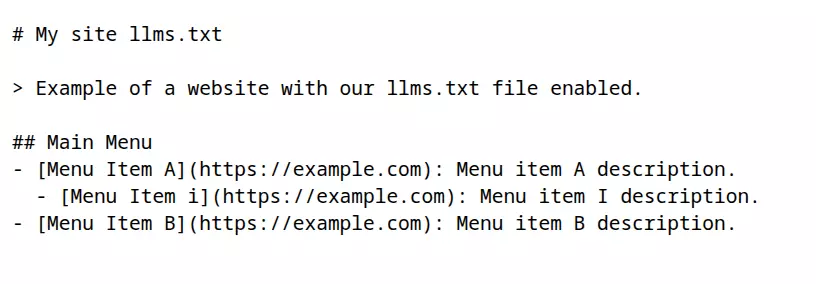
El resultado usando como ejemplo el token que incluye los enlaces del menú principal, al navegar a la ruta /llms.txt sería el siguiente:
Conclusión: Prepararse para el futuro de las búsquedas
En resumen, aunque aún no se ha demostrado que el estándar llms.txt mejore el posicionamiento en los resultados de búsqueda de la misma manera que el SEO tradicional, su implementación es rápida, sencilla y gratuita, lo que lo convierte en un experimento de bajo esfuerzo con un gran potencial para cualquier marca con visión de futuro.
En última instancia, la IA está transformando de forma radical las formas tradicionales en las que hemos interactuado con Internet hasta ahora. Aceptar este cambio, aunque sea de forma experimental, es una medida estratégica para mantenerse a la vanguardia, lo que nos permite observar de primera mano cómo los modelos de IA están adoptando y utilizando estos nuevos conceptos para interpretar nuestra presencia digital.
